Why Binary Search Is Preferred Over Ternary Search Despite log₃(n)
A system-aware breakdown of why binary search outperforms ternary search despite the theoretical log_3(n) edge.
Algorithms rarely fail because they are incorrect.
They fail because assumptions that look valid mathematically do not survive contact with real machines.
Ternary search is a classic example.
Yet binary search remains the default — in standard libraries, production systems, and performance-critical code.

This article takes a theoretical yet system-aware approach to explain:
- Why ternary search looks faster mathematically
- Why that advantage does not translate to real performance
- How constant factors dominate asymptotic gains
- How CPU architecture, branching, and memory access change the outcome
- Why binary search is an optimal engineering choice for discrete sorted data
Searching as an Optimization Problem
At a high level, searching is an optimization problem.
Given:
- A sorted array of size N
- A target value
- A machine with finite compute, cache, and memory bandwidth
The goal is simple:
Determine presence or absence of the target with minimal cost.
Every search step has a cost:
- Comparisons
- Branches
- Memory accesses
- Cache behavior
- Pipeline effects
Big-O notation describes growth, but real performance is determined by work per step.
Binary Search: The Baseline
Binary search divides the search space into two equal parts.
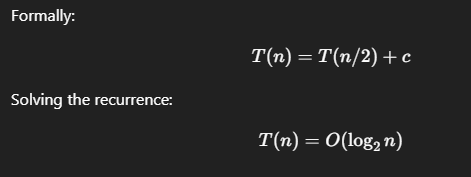
Each iteration performs:
- One midpoint calculation
- One comparison
- One branch decision
- One memory access
It eliminates 50% of the search space per step with minimal work.
Ternary Search: The Theoretical Improvement
Ternary search divides the array into three equal parts using two midpoints.

…it appears ternary search should always win.
But this conclusion hides an important detail.
Full Implementation: Ternary Search (Discrete Array)
To reason about performance, we first need a correct, canonical implementation.
def ternary\_search(arr, target):
low, high = 0, len(arr) - 1
while low <= high:
third = (high - low) // 3
mid1 = low + third
mid2 = high - third
if arr\[mid1\] == target:
return mid1
if arr\[mid2\] == target:
return mid2
if target < arr\[mid1\]:
high = mid1 - 1
elif target > arr\[mid2\]:
low = mid2 + 1
else:
low = mid1 + 1
high = mid2 - 1
return -1What Happens Per Iteration
- Two midpoint calculations
- Two equality comparisons
- Multiple branch paths
- Two memory accesses
Iteration count is lower — work per iteration is higher.
Binary Search Implementation (Baseline)
def binary\_search(arr, target):
low, high = 0, len(arr) - 1
while low <= high:
mid = (low + high) // 2
if arr\[mid\] == target:
return mid
elif target < arr\[mid\]:
high = mid - 1
else:
low = mid + 1
return -1This version:
- Uses a single midpoint
- Has fewer comparisons
- Has simpler control flow
Mathematical Comparison: log₂(n) vs log₃(n)

This is where the misconception starts.
Visualizing the Difference
import math
import matplotlib.pyplot as plt
n\_values = \[10\*\*i for i in range(1, 8)\]
log2\_values = \[math.log2(n) for n in n\_values\]
log3\_values = \[math.log(n, 3) for n in n\_values\]
plt.plot(n\_values, log2\_values, label="log₂(n)")
plt.plot(n\_values, log3\_values, label="log₃(n)")
plt.xscale("log")
plt.xlabel("n (array size)")
plt.ylabel("Iterations")
plt.title("Theoretical Iteration Count")
plt.legend()
plt.show()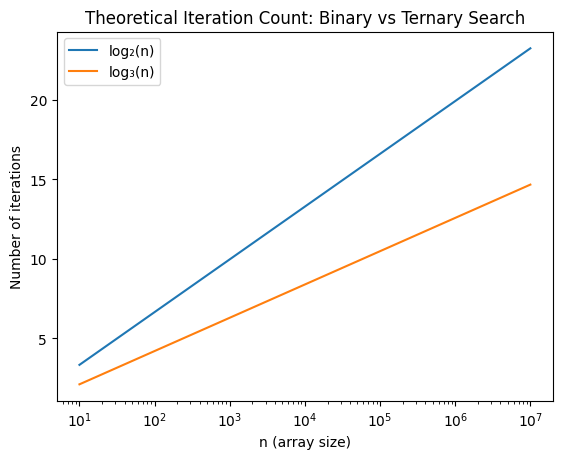
What the Graph Shows
- log₃(n) grows slower
- The gap remains small even for large n
What the Graph Hides
- Cost per iteration
- Branch mispredictions
- Cache misses
The Hidden Cost: Constant Factors
Let:
- Binary iteration cost = c
- Ternary iteration cost = 2c
Total work:
- Binary: c⋅log2n
- Ternary: 2c⋅log3n
Substituting:

➡️ Ternary search does more total work.
CPU Branch Prediction and Pipeline Effects
Modern CPUs optimize predictable execution.
Binary search:
- Simple branching
- High predictability
- Stable pipelines
Ternary search:
- More branches
- Multiple decision paths
- More mispredictions
Branch mispredictions cause pipeline flushes — costing far more than arithmetic.
Memory Access and Cache Locality
Memory access dominates runtime.
Binary search:
- One memory access per iteration
- Better cache locality
Ternary search:
- Two distant memory accesses
- Higher cache miss probability
Cache misses cost orders of magnitude more than comparisons.
Empirical Benchmark: Binary vs Ternary Search
Theory is not enough. We measure.
import time
import random
def benchmark(search\_fn, arr, targets):
start = time.perf\_counter()
for t in targets:
search\_fn(arr, t)
return time.perf\_counter() - start
N = 10\_000\_000
arr = list(range(N))
targets = \[random.randint(0, N \* 2) for \_ in range(100\_000)\]
\# Warm-up
binary\_search(arr, targets\[0\])
ternary\_search(arr, targets\[0\])
binary\_time = benchmark(binary\_search, arr, targets)
ternary\_time = benchmark(ternary\_search, arr, targets)
print(f"Binary Search Time : {binary\_time:.4f} seconds")
print(f"Ternary Search Time : {ternary\_time:.4f} seconds")
Observed Results
- Binary search consistently faster
- Lower variance
- More predictable latency
Even with fewer iterations, ternary search loses.
Why Standard Libraries Use Binary Search
Standard libraries optimize for:
- Predictability
- Cache efficiency
- Simplicity
- Minimal worst-case cost
Binary search satisfies all four.
Ternary search increases:
- Comparisons
- Branches
- Memory pressure
- Bug surface
Where Ternary Search Actually Wins
Ternary search is ideal for unimodal optimization problems, not discrete lookup.
Example:
- Finding maximum/minimum of a function that increases then decreases
Binary search ❌
Ternary search ✅
The algorithm is useful — just not for array lookup.
Generalizing the Insight: Why k-array Search Fails
Increasing splits:
- Reduces depth
- Explodes per-step cost
Binary search represents the optimal balance between depth reduction and operational simplicity.
Final Thought
Ternary search is faster in theory.
Binary search is faster in reality.
This is not a contradiction.
Algorithms do not run on math.
They run on machines.
Binary search survives because it minimizes total work, not iteration count — respecting CPUs, caches, and real constraints.
That is why, decades later, it still wins.